老铁们,知道今天是什么日子吗?
明知应该说声节日快乐,但咱们也不能忘记在寒冷狗窝里坐等国家分配的单身汪们(仿佛说的不是我自己)。

今天一早,当发现朋友圈撒的狗粮已经够吃一年后,我还是打开了网易云音乐,想在热闹的评论区寻找同类:另一群单身狗们。
没想到,他们除了搞出个“单身元年特别访谈”,每日推荐给我推的第一首歌竟然是:
The Best Day of My Life(我人生中最好的一天)。
……
好吧,歌词“我不会自暴自弃,不要唤醒我,这是我人生中最美好的一天”,让我严重怀疑,网易云音乐的个性推荐已经洞悉了所有单身狗用户的生活常态:
“别总在评论区呆着了,请在下个元年来之前,找到自己的幸福。要不然,狗年一过,你的头衔就会变成‘单身猪’。”
情人节快乐,狗年快乐。

在知乎上,“网易云音乐的歌单推荐算法是怎样的”与“网易云音乐到底好在哪里”这两个问题,分别占据了“网易云音乐”热门话题的第三与第八位。
而很大程度上,第一个问题成就了第二个问题。
或许网易云音乐在知乎上好评一边倒的原因五花八门(有人说雇了大量水军,如果是这样,那应该是笔重金投入。我不会告诉你两个平台的社群重合度很大的),但歌单质量硬,且个性推荐对比国内竞品相对精准,是让一部分用户发展成为网易云音乐死忠粉的关键原因之一。
以及,第一个问题也可以解释,为何你在很多歌的评论区里,都会看到像“日推第一”、“日推第二”、“日推+FM同时推荐”这类的大量评论。
然而,有人把网易云音乐比作是”独立且小众音乐爱好者的天堂“其实并不十分贴切。将那些被大众忽视的歌重新曝光于你的眼下,很多时候是技术在背后起的作用。
就像你今天下载了一首周杰伦的歌,系统第二天是推给你周杰伦另一首曲风类似的热门歌曲,还是推一首曲风类似的冷门歌曲,更会让你感到新奇?
这个答案有点真相
不过倒是让人有点惊讶,网易云音乐从来没有官方披露过自己的推荐算法与产品应用细节。但这不妨碍大众对其技术与产品融合的过程产生兴趣。
因此,网易云音乐里的算法模型与 AI应用,基本已经被知乎用户们扒了个底朝天了。
你完全可以在“网易云音乐的歌单推荐算法是怎样的”这个知乎话题里找到非常棒的解答与推测(里面的高赞答案比媒体的报道简直不要清楚太多,讲的明白易懂)。
而我们之所以要拜访网易云音乐的数据挖掘工程师徐家与产品经理沈博文,与其说是揭开算法秘密,不如说是验证此前(包括网络上)的种种猜测,以及帮用户们解答在使用网易云音乐过程中产生的疑惑。
基础算法:人以群分
实际上,网易云音乐个性化推荐的算法与今日头条、B站还有很多 O2O 电商平台应用的基础推荐算法大同小异。这个得到了徐家的认证,就是我们熟知的那类基础算法:
协同过滤算法
这个算法要归功于亚马逊工程师的发明——一个客户买了这个东西,那么他也可能买另一个东西。
简单来说,该算法的预测标准取决于人与人之间相似的消费模式。譬如,我喜欢这两首歌,而你的歌单里也有这两首歌,所以你歌单里有可能存在其他我喜欢的歌。
以上的说法只是便于理解。实际上,协同过滤算法其实应该分为两类:基于用户与基于项目(单曲)。
1、基于用户:我与小明收藏的歌单相似度很高,那么在判断我们口味相似的基础上,可以给小明推荐我歌单里她没收藏过的单曲。
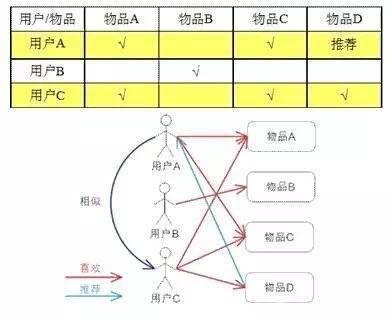
图片来源:数据挖掘工人
2、基于项目(单曲):就是将用户对一首歌的偏好作为向量计算单曲之间的相似度,比对相似度后,根据这个用户历史偏好为另一位用户推荐单曲。
举个例子,小歆下载了《勇气》《小情歌》两首单曲,而小宜下载了《勇气》《天黑黑》和《小情歌》,而小艺下载了《勇气》…
那么根据这些用户的历史偏好,网易云音乐可以判断《勇气》与《小情歌》是相似的,喜欢《勇气》的可能也会喜欢《小情歌》,那么可以把《小情歌》推荐给小艺。
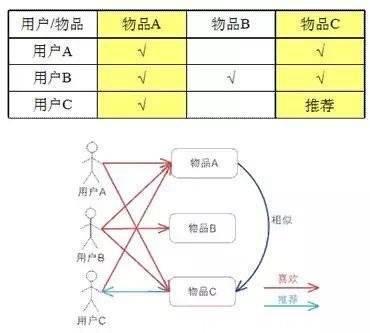
图片来源:数据挖掘工人
总之,如果你觉得对于“协同过滤”这种算法仍然理解困难,那可以只记住一个词:人以群分。
在这里要歪个楼:正是这种本质上基于用户偏好相似度的推荐模型,在无形中让用户在听音乐中组成了一个个“彼此聊得来”的社群。
因此,沈博文并没有把“以后可能会发展成全国最大的婚恋交友网站”看作是一个无厘头的笑话。而是认为这种基于音乐喜好的社交趋势,反而比当下的交友平台更靠谱:
好奇心日报之前曾做过一个调查,有关于人类找到灵魂伴侣的主要参考标准是什么?——是音乐品味。
神经网络模型下的“物以类聚”
可以看到,这种推荐算法绝对缺不了用户历史数据的支撑。在数据量庞大且足够干净的时候,协同过滤算法是非常强大的。
那么反过来想,假如我是一个新用户,或者我使用网易云音乐的频率特别低。也就是说,在数据稀少的情况下,网易云音乐该怎么获知我的口味?
这种冷启动问题,意味着不同算法模型交叉使用的必然性。或许下面的第二大类算法能在一定程度上消除这个障碍。
基于内容的推荐算法。
这是以区分单曲内容实质为核心的推荐方式,就看做是“物以类聚”吧。
全球著名音乐流媒体平台 Spotify内容推荐模型的建立者之一 Sander Dieleman(现在是 DeepMind研究科学家),曾在一篇名为《卷积神经网络在音乐推荐里的应用》的博文中具体阐释了使用单一协同过滤算法会存在的误差:
1.由于这种算法除了用户及消费模式信息外,不涉及被推荐单曲本身的任何信息。因此,热门音乐就比冷门音乐更容易得到推荐,因为前者拥有更多的数据。而这种推荐往往是很难让人感到惊喜的。
2.而基于项目(单曲)的协同过滤,也有一个问题,就是相似使用模式下的内容异质。
例如你听了一张新专辑里面全部的歌,但除了主打歌,其他的一些插曲、翻唱曲以及混音曲可能都不是歌手的典型作品,那么协同过滤在这个时候,就会因为这些「噪音」而产生偏差。
当然,它最大的问题便是“没有数据,一切皆失效”。
因此,基于内容的推荐算法更像是对协同过滤算法以上缺陷的一种补充——假如没有大量用户数据,或者想听冷门歌曲,我们就只能从音乐本身寻找答案了。
徐家与沈博文两位专家明确表示,网易云音乐针对这些问题采取了基于内容的复杂算法。但较为遗憾,二位对具体细节并没有进行过多解释。
因此,根据我们的猜测,他们运用的应该与 Spotify、Youtube等流媒体平台一样的方法——利用深度学习建立基于音频的推荐模型。
首先,如果要对比单曲与单曲之间的内容差异,那么维度就太多了,譬如艺术家及专辑信息、歌词、音乐本身的旋律及节奏、评论区里的夸夸其谈、VIP下载歌曲、付费与否等等元素。
可以想象,这是一个多么庞大的计算量。不过暴力全量计算不失为一种方法……
因此,要通过特征 embedding和降维方法,把这么多特征映射到低维的隐变量空间里(如同下图)。
可想而知,在这个空间里,每首歌都可以有一个坐标,而坐标数值就是包括音频特征、用户偏好在内的多重编码信息。
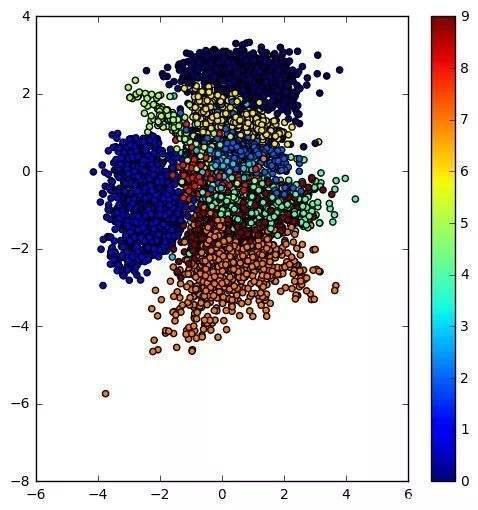
那么,假如我们直接预测了一首歌曲在这个低维空间中的准确位置,也就明确了这首歌的表征(包括用户偏好信息)。
这样就能够把它推荐给合适的听众,且并不需要历史使用数据。
因此,掌握了大量歌曲数据源信息与用户行为数据映射出来的隐含特征,再以此建立基于音频特征的神经网络预测模型,用短音频片段训练网络,是很多流媒体正在采取的方式。(具体方法可以去翻翻 Sander Dieleman的论文,如果你懂这个,给我们来讲一课!)
当然,在训练网络过程中,工程师门还是会通过“丢弃”(Dropout)等方法来降低过滤模型隐藏表征与音频预测之间的标准差(不能让数据集离散度太高),而这样做主要是为了降低歌曲人气对推荐系统的影响。
没错,这就是你能够收到更加小众歌曲推荐的缘由。
当然,以上无论哪种算法,其实都会基于一定的“相似度”。
譬如网易云音乐也同时应用了机器学习排序模型,这种模型仍然是基于用户行为数据与相似度(也是很普遍的一种模型)。
体现在应用上,通俗来讲,就是你的“每日推荐”歌单里,第一首歌通常是系统认为与你的喜好匹配度最高的一首“很多人常常在评论区喊出的‘日推第一’,其意义还是蛮大的”。
而知乎里有大 V提到的推荐模型“潜在因子矩阵”,徐家则认为已经过时了,现在用的人已经很少。
计算方法——我们歌单相似度到底怎么算出来的?
据徐家透露,网易云音乐则主要运用了两种度量方式:
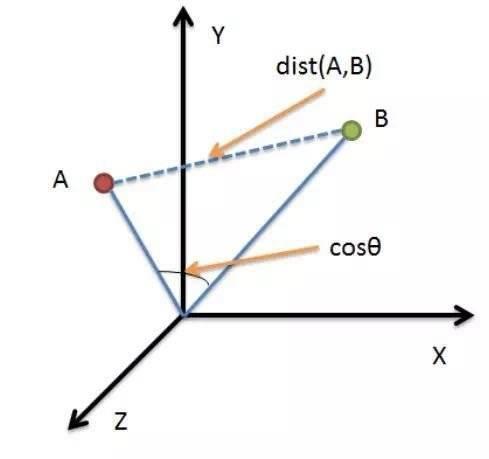
欧式距离与余弦相似度。
CDSN一位技术专家的博客已经把两者之间的差异解释的非常清晰了(下图):
来自名为Ying的CDSN技术博客
前者是被看作坐标系中的两个点,来计算两点之间的距离。
譬如上图数据 A和 B在坐标图中当做点时,两者相似度为两点之间的绝对距离 dist(A,B)。
而后者是看成坐标系中两个向量,来计算两向量之间的夹角。
譬如图中的 cosθ,夹角越小,相似度越高。
你会发现,仍然是在这张图上,如果 B的位置不变,A点的位置沿 A到原点这条线的反方向不断延伸,A与 B的余弦夹角就是永远不变的,但两点的绝对距离却发生了变化。
这种差异,导致他们需要被用于不同的数据分析模型。
徐家解释,能够突出数值绝对差异的欧氏距离,在计算歌曲本身相似度时用的比较多。
举个例子,A歌曲 1万人喜欢,而 B歌曲 2万人喜欢,由于样本量足够大了,可以把所有用户对歌曲的喜好看成一样的强度,那么就可以直接用欧式距离来算。
在欧式距离下,用户对歌曲的偏好都可以被认为是一样的分数,可以简化歌曲相似度的计算。
而余弦相似度更多是从用户偏好方向上区分差异。
譬如网易云音乐可以用该方法,通过用户对内容评分(有下载、收藏、搜索、不感兴趣等不同评分权重)来区分用户兴趣的相似度。
总之,结合了上述算法与计算方式,网易云音乐的个性推荐在大众里的口碑还不错。
但这种“还不错”,如果仅仅依靠技术就能达成,恐怕亚马逊在中国的业务就不会这么糟糕了(我其实在吐槽它的界面)。
坦白讲,再牛逼的算法也有不足。
对于所有音乐产品,用户体验的分值都是由编辑及项目协作、界面设计喜好、音乐版权丰富程度以及音乐偏好预测、技术能力、问题反馈速度共同构成的。
这也是为何有人为网易云音乐的推荐歌单疯狂打 Call,而也有不少人称,“听歌比较杂的人可能用网易云音乐真的很心累”。
举个例子,你是一个忠实的欧美音乐圈粉丝,但却在最近偶尔下载了一首中文歌。
那么我可以确定,你第二天的推荐歌单里,一定会有一首中文歌。接下来只能不停地对出现在歌单里的中文歌狂点“不感兴趣”了。
推荐算法设定了基于不同用户行为的权重,“下载”最高,收藏、搜索、分享其次,此外你也可以点击“不感兴趣”,或许会避开这类歌。
人工不可缺少
除了算法推荐,在很大程度上,一个流媒体平台也一定会承担人工过滤职责,从产品及运营角度确立人工规则,筛除不符合条件的选项。
沈博文告诉我们,他们不只是依赖算法,而是希望通过一些人工的力量,来补偿算法的一些不足。
因此,除了有单独的算法团队,网易云音乐也有一个强大的编辑团队。
一方面,他们帮助在一开始推荐内容上面做一层筛选,找出那些比较优质的内容,保证整一个推荐库的健康。
而另一方面,他们也需要解决算法的一些收敛问题。
“因为如果纯粹依靠算法推荐的话可能会对一些新内容响应较慢,我们也会用一些人工编辑的方式。去寻找出一些可能我们觉得非常优质的内容,然后推荐给大家”,沈博文表示。
此外,即便客服系统在一定程度上依赖AI技术,但由网易云音乐客服部门与技术部门共同组成的“人工反馈小组”,才是让用户对网易云音乐好感up的重要原因。
很多“秒回”的技术解决方案还被用户戏称为“原来网易云音乐的小编真的是活的”。
在平台发展初期,数据量尚不能满足建立推荐算法模型时,就像知乎一位名叫沙克的互联网作者描述的那样:
你之所以能得到高逼格推荐,很可能就是最早来源于一个名为”高逼格小清新“专业编辑推荐歌单。
他们有效地引导了兴趣相投的用户去发现这些音乐,大多跟你有相似品味的人都听过并感觉不错,再经过 fancy的算法”沉淀“、”发酵“,继而产生了很好的相似度,从而生成了了这么优秀的推荐并推送了给了你。
最后,大家被“惊艳”到了,更多的新用户加入,Perfect。



