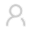
1 用字符串表示的数据类型
2 示例:电影评论的情感分析

作为一个运行示例,我们将使用由斯坦福研究员Andrew Maas 收集的IMDb(Internet Movie Database,互联网电影数据库)网站的电影评论数据集。 这个数据集包含评论文本,还有一个标签,用于表示该评论是“正面的”(positive)还是“负面的”(negative)。IMDb 网站本身包含从1 到10 的打分。为了简化建模,这些评论打分被归纳为一个二分类数据集,评分大于等于7 的评论被标记为“正面的”,评分小于等于4 的评论被标记为“负面的”,中性评论没有包含在数据集中。我们不讨论这种方法是否是一种好的数据表示,而只是使用Andrew Maas 提供的数据。
将数据解压之后,数据集包括两个独立文件夹中的文本文件,一个是训练数据,一个是测试数据。每个文件夹又都有两个子文件夹,一个叫作pos,一个叫作neg:
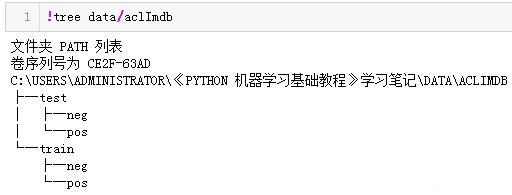
pos 文件夹包含所有正面的评论,每条评论都是一个单独的文本文件,neg 文件夹与之类似。scikit-learn 中有一个辅助函数可以加载用这种文件夹结构保存的文件,其中每个子文件夹对应于一个标签,这个函数叫作load_files。我们首先将load_files 函数应用于训练数据:
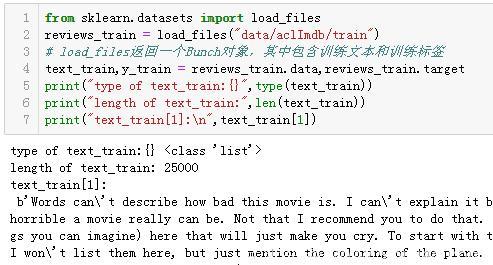
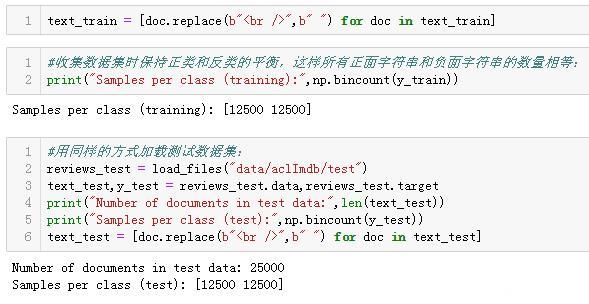
你可以看到,text_train 是一个长度为25 000 的列表,其中每个元素是包含一条评论的字符串。我们打印出索引编号为1 的评论。你还可以看到,评论中包含一些HTML 换行符(<br />)。虽然这些符号不太可能对机器学习模型产生很大影响,但最好在继续下一步之前清洗数据并删除这种格式:
 3 将文本数据表示为词袋
3 将文本数据表示为词袋用于机器学习的文本表示有一种最简单的方法,也是最有效且最常用的方法,就是使用词袋(bag-of-words)表示。使用这种表示方式时,我们舍弃了输入文本中的大部分结构,如章节、段落、句子和格式,只计算语料库中每个单词在每个文本中的出现频次。舍弃结构并仅计算单词出现次数,这会让脑海中出现将文本表示为“袋”的画面。
对于文档语料库,计算词袋表示包括以下三个步骤。
(1) 分词(tokenization)。将每个文档划分为出现在其中的单词[ 称为词例(token)],比如按空格和标点划分。
(2) 构建词表(vocabulary building)。收集一个词表,里面包含出现在任意文档中的所有词,并对它们进行编号(比如按字母顺序排序)。
(3) 编码(encoding)。对于每个文档,计算词表中每个单词在该文档中的出现频次。
在步骤1 和步骤2 中涉及一些细微之处,我们将在本章后面进一步深入讨论。目前,我们来看一下如何利用scikit-learn 来应用词袋处理过程。图7-1 展示了对字符串"This ishow you get ants." 的处理过程。其输出是包含每个文档中单词计数的一个向量。对于词表中的每个单词,我们都有它在每个文档中的出现次数。也就是说,整个数据集中的每个唯一单词都对应于这种数值表示的一个特征。请注意,原始字符串中的单词顺序与词袋特征表示完全无关。
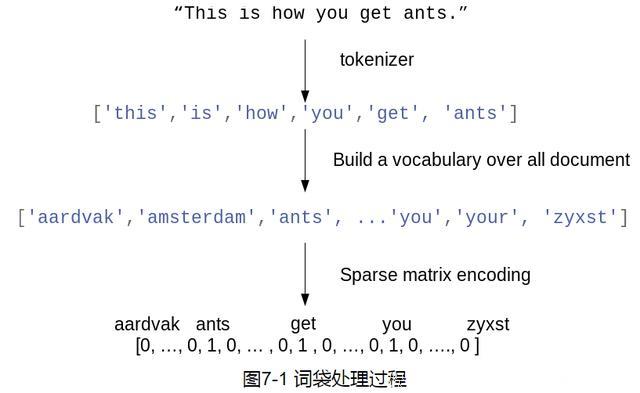
3.1 将词袋应用于玩具数据集
词袋表示是在CountVectorizer 中实现的,它是一个变换器(transformer)。我们首先将它应用于一个包含两个样本的玩具数据集,来看一下它的工作原理:
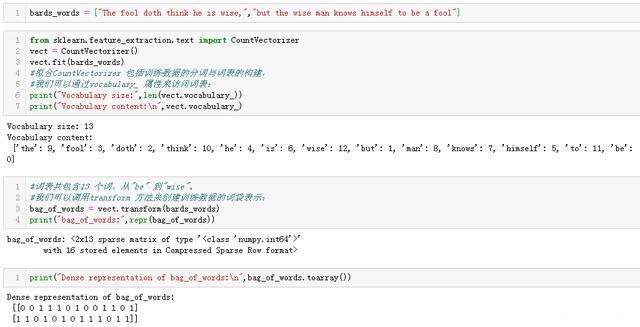
词袋表示保存在一个矩阵中,矩阵的形状为2×13,每行对应于两个数据点之一,每个特征对应于词表中的一个单词。这里使用稀疏矩阵,是因为大多数文档都只包含词表中的一小部分单词,也就是说,特征数组中的大部分元素都为0。要想查看矩阵的实际内容,可以使用toarray 方法将其转换为NumPy 数组。
我们可以看到,每个单词的计数都是0 或1。bards_words 中的两个字符串都没有包含相同的单词。我们来看一下如何阅读这些特征向量。第一个字符串("The fool doth think heis wise,")被表示为第一行,对于词表中的第一个单词"be",出现0 次。对于词表中的第二个单词"but",出现0 次。对于词表中的第三个单词"doth",出现1 次,以此类推。通过观察这两行可以看出,第4 个单词"fool"、第10 个单词"the" 与第13 个单词"wise" 同时出现在两个字符串中。
由于内容与代码很多,从此处向下只给出简单的提纲。具体内容可以点击http://wuming.ntzx.cn/mod/resource/view.php?id=510
3.2 将词袋应用于电影评论上一节我们详细介绍了词袋处理过程,下面我们将其应用于电影评论情感分析的任务。前面我们将IMDb 评论的训练数据和测试数据加载为字符串列表(text_train 和text_test)。
4 停用词删除没有信息量的单词还有另一种方法,就是舍弃那些出现次数太多以至于没有信息量的单词。有两种主要方法:使用特定语言的停用词(stopword)列表,或者舍弃那些出现过于频繁的单词。scikit-learn 的feature_extraction.text 模块中提供了英语停用词的内置列表。
5 用tf-idf缩放数据另一种方法是按照我们预计的特征信息量大小来缩放特征,而不是舍弃那些认为不重要的特征。最常见的一种做法就是使用词频- 逆向文档频率(term frequency–inverse documentfrequency,tf-idf)方法。这一方法对在某个特定文档中经常出现的术语给予很高的权重,但对在语料库的许多文档中都经常出现的术语给予的权重却不高。如果一个单词在某个特定文档中经常出现,但在许多文档中却不常出现,那么这个单词很可能是对文档内容的很好描述。
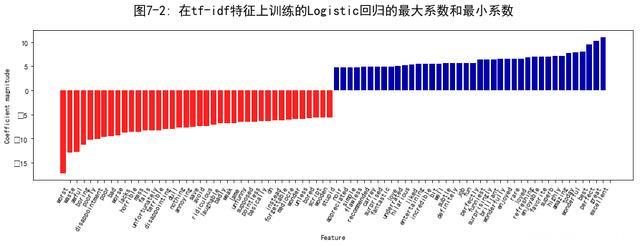
6 研究模型系数最后,我们详细看一下Logistic 回归模型从数据中实际学到的内容。由于特征数量非常多(删除出现次数不多的特征之后还有27 271 个),所以显然我们不能同时查看所有系数。但是,我们可以查看最大的系数,并查看这些系数对应的单词。我们将使用基于tf-idf 特征训练的最后一个模型。
下面这张条形图(图7-2)给出了Logistic 回归模型中最大的25 个系数与最小的25 个系数,其高度表示每个系数的大小:
 7 多个单词的词袋(n元分词)
7 多个单词的词袋(n元分词)使用词袋表示的主要缺点之一是完全舍弃了单词顺序。因此,“it’s bad, not good at all”(电影很差,一点也不好)和“it’s good, not bad at all”(电影很好,还不错)这两个字符串的词袋表示完全相同,尽管它们的含义相反。将“not”(不)放在单词前面,这只是上下文很重要的一个例子(可能是一个极端的例子)。幸运的是,使用词袋表示时有一种获取上下文的方法,就是不仅考虑单一词例的计数,而且还考虑相邻的两个或三个词例的计数。
两个词例被称为二元分词(bigram),三个词例被称为三元分词(trigram),更一般的词例序列被称为n 元分词(n-gram)。我们可以通过改变CountVectorizer 或TfidfVectorizer的ngram_range 参数来改变作为特征的词例范围。ngram_range 参数是一个元组,包含要考虑的词例序列的最小长度和最大长度。
8 高级分词、词干提取和词形还原如前所述,CountVectorizer 和TfidfVectorizer 中的特征提取相对简单,还有更为复杂的方法。在更加复杂的文本处理应用中,通常需要改进的步骤是词袋模型的第一步:分词(tokenization)。这一步骤为特征提取定义了一个单词是如何构成的。
我们前面看到,词表中通常同时包含某些单词的单数形式和复数形式,比如"drawback"和"drawbacks"、"drawer" 和"drawers"、"drawing" 和"drawings"。对于词袋模型而言,"drawback" 和"drawbacks" 的语义非常接近,区分二者只会增加过拟合,并导致模型无法充分利用训练数据。同样我们还发现,词表中包含像"replace"、"replaced"、"replacement"、"replaces" 和"replacing" 这样的单词,它们都是动词“to replace”的不同动词形式或相关名词。与名词的单复数形式一样,将不同的动词形式及相关单词视为不同的词例,这不利于构建具有良好泛化性能的模型。
这个问题可以通过用词干(word stem)表示每个单词来解决,这一方法涉及找出[ 或合并(conflate)] 所有具有相同词干的单词。如果使用基于规则的启发法来实现(比如删除常见的后缀),那么通常将其称为词干提取(stemming)。如果使用的是由已知单词形式组成的字典(明确的且经过人工验证的系统),并且考虑了单词在句子中的作用,那么这个过程被称为词形还原(lemmatization),单词的标准化形式被称为词元(lemma)。词干提取和词形还原这两种处理方法都是标准化(normalization)的形式之一,标准化是指尝试提取一个单词的某种标准形式。标准化的另一个有趣的例子是拼写校正,这种方法在实践中很有用,但超出了本书的范围。
9 主题建模与文档聚类常用于文本数据的一种特殊技术是主题建模(topic modeling),这是描述将每个文档分配给一个或多个主题的任务(通常是无监督的)的概括性术语。这方面一个很好的例子是新闻数据,它们可以被分为“政治”“体育”“金融”等主题。如果为每个文档分配一个主题,那么这是一个文档聚类任务。如果每个文档可以有多个主题,那么这个任务是一种成分分解。每个成分对应于一个主题,文档表示中的成分系数告诉我们这个文档与该主题的相关性强弱。通常来说,人们在谈论主题建模时,他们指的是一种叫作隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)的特定分解方法。
隐含狄利克雷分布
从直观上来看,LDA 模型试图找出频繁共同出现的单词群组(即主题)。LDA 还要求,每个文档可以被理解为主题子集的“混合”。重要的是要理解,机器学习模型所谓的“主题”可能不是我们通常在日常对话中所说的主题,而是更类似于PCA 或NMF所提取的成分,它可能具有语义,也可能没有。即使LDA“主题”具有语义,它可能也不是我们通常所说的主题。回到新闻文章的例子,我们可能有许多关于体育、政治和金融的文章,由两位作者所写。在一篇政治文章中,我们预计可能会看到“州长”“投票”“党派”等词语,而在一篇体育文章中,我们预计可能会看到类似“队伍”“得分”和“赛季”之类的词语。这两组词语可能会同时出现,而例如“队伍”和“州长”就不太可能同时出现。但是,这并不是我们预计可能同时出现的唯一的单词群组。这两位记者可能偏爱不同的短语或者选择不同的单词。可能其中一人喜欢使用“划界”(demarcate)这个词,而另一人喜欢使用“两极分化”(polarize)这个词。其他“主题”可能是“记者A 常用的词语”和“记者B 常用的词语”,虽然这并不是通常意义上的主题。
10 小结与展望本章讨论了处理文本[ 也叫自然语言处理(NLP)] 的基础知识,还给出了一个对电影评论进行分类的示例应用。如果你想要尝试处理文本数据,那么这里讨论的工具应该是很好的出发点。特别是对于文本分类任务,比如检测垃圾邮件和欺诈或者情感分析,词袋模型提供了一种简单而又强大的解决方案。正如机器学习中常见的情况,数据表示是NLP 应用的关键,检查所提取的词例和n 元分词有助于深入理解建模过程。在文本处理应用中,对于监督任务与无监督任务而言,通常都可以用有意义的方式对模型进行内省,正如我们在本章所见。在实践中使用基于NLP 的方法时,你应该充分利用这一能力。
自然语言和文本处理是一个很大的研究领域,讨论其高级方法的细节已经远远超出了本书范围。如果你想学习更多内容,我们推荐阅读Steven Bird、Ewan Klein 和EdwardLoper 合著的Natural Language Processing with Python 一书,其中给出了NLP 的概述,并介绍了nltk 这个用于NLP 的Python 库。另一本很好且概念性更强的书是Christopher Manning、PrabhakarRaghavan 和Hinrich Schuütze 合著的标准参考,Introduction to Information Retrieval,其中介绍了信息检索、NLP 和机器学习中的基本算法。这两本书都有可以免费访问的在线版本。如前所述,CountVectorizer 类和TfidfVectorizer 类仅实现了相对简单的文本处理方法。对于更高级的文本处理方法,我们推荐使用Python 包spacy(一个相对较新的包,但非常高效,且设计良好)、nltk(一个非常完善且完整的库,但有些过时)和gensim(着重于主题建模的NLP 包)。
近年来,在文本处理方面有许多非常令人激动的新进展,这些内容都超出了本书的范围,并且都和神经网络有关。第一个进展是使用连续向量表示,也叫作词向量(word vector)或分布式词表示(distributed word representation), 它在word2vec 库中实现。ThomasMikolov( 等人的原始论文)“Distributed Representations of Words and Phrases and TheirCompo sitionality”是对这一主题的很好介绍。对于这篇论文及其后续所讨论的技术,spacy 和gensim 都提供了相应的功能。
近年来,NLP 还有另一个研究方向不断升温,就是使用递归神经网络(recurrent neuralnetwork,RNN)进行文本处理。与只能分配类别标签的分类模型相比,RNN 是一种特别强大的神经网络,可以生成同样是文本的输出。能够生成文本作为输出,使得RNN非常适合自动翻译和摘要。Ilya Suskever、Oriol Vinyals 和Quoc Le 的一篇技术性相对较强的文章“Sequence to Sequence Learning with Neural Networks”对这一主题进行了介绍。在TensorFlow 网站上可以找到使用tensorflow 框架的更为实用的教程。
【说明:从3.2节起内容只是提纲工的说明,具体内容请点击http://wuming.ntzx.cn/mod/resource/view.php?id=510】
全文完



